AWS API Gateway Private Endpoints is a feature of Amazon API Gateway that allows you to expose your APIs privately within your Amazon Virtual Private Cloud (VPC). This feature ensures that API traffic is confined within the AWS network, bypassing the public internet entirely. These endpoints are made possible through the integration of API Gateway with AWS PrivateLink, a technology that securely connects services across different AWS accounts and VPCs without requiring public IP addresses or the need to manage firewall and route tables. With API Gateway Private Endpoints, you create private APIs that are accessible only from within your VPC or from those VPCs to which you have provided access via VPC peering, AWS Transit Gateway, or Direct Connect. Here’s a image that illustrates this behaviour:
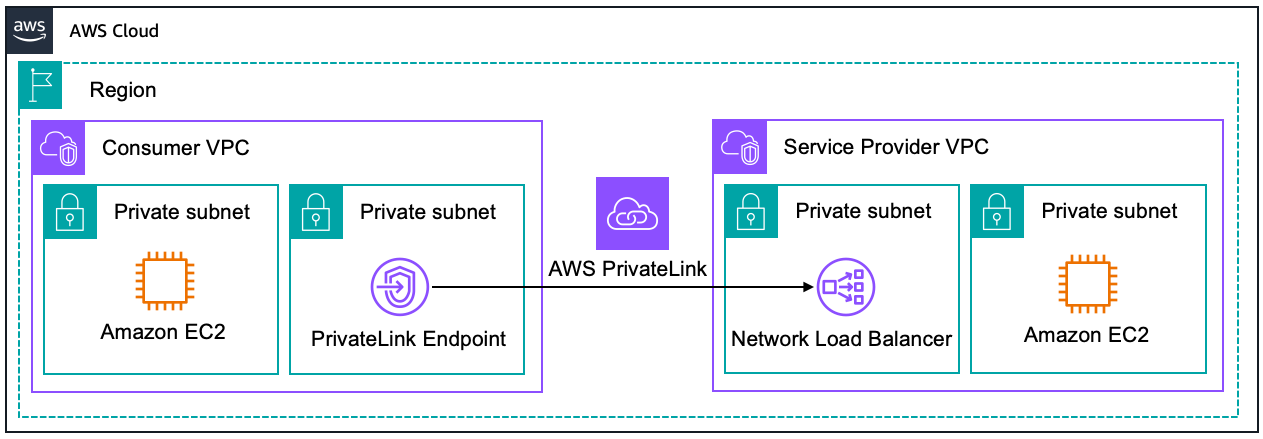
API Gateway Private Endpoints are important because they ensure that sensitive API traffic is not exposed over the internet. This is crucial for businesses operating under strict regulatory requirements, as it minimizes the risk of data breaches and unauthorized access. Moreover, keeping traffic internal reduces latency and potential exposure points, contributing to both performance and security improvements.
For example, consider a financial services company that operates within a tightly regulated industry. They need to process confidential financial transactions and must ensure that all data handling complies with industry regulations such as PCI-DSS or GDPR. By using API Gateway Private Endpoints, they can route all their API traffic through the private network of their Amazon Virtual Private Cloud (VPC), significantly reducing the risk of data exposure and enabling compliance with these regulatory requirements. This setup not only secures the data but also often improves the response times of the APIs by minimizing the distance data travels.
To learn more about the evolution of private endpoints in AWS, refer to this AWS blog.
Deploying with AWS CDK
In the previous post, I’ve explained the benefits of deploying AWS resources progammatically with Infrastructure as Code (IaC). Therefore, I prefer deploying the AWS API Gateway Private Endpoint via AWS CDK. The code below shows how to do it in Typescript, feel free to modify the properties based on your use case.
I refered to this AWS blog and AWS CDK documention for deployment.
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as lambda from 'aws-cdk-lib/aws-lambda';
import * as ec2 from 'aws-cdk-lib/aws-ec2';
import * as dotenv from "dotenv";
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as path from 'path';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as apiGateway from 'aws-cdk-lib/aws-apigateway';
// Stack is a logical grouping of AWS resources
export class InfraStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Creating the VPC and subnets
const vpc = new ec2.Vpc(this, "myVPC", {
vpcName: "myVPC",
ipAddresses: ec2.IpAddresses.cidr('10.0.0.0/16'),
availabilityZones: ["ap-southeast-2a", "ap-southeast-2b"],
enableDnsHostnames: true,
enableDnsSupport: true,
subnetConfiguration: [
{
name: "private-subnet",
subnetType: ec2.SubnetType.PRIVATE_ISOLATED,
cidrMask: 20,
}
],
});
// Creating the VPC Endpoint to Execute the API
const vpcEndpoint = new ec2.InterfaceVpcEndpoint(this, 'VPC Endpoint', {
vpc,
service: new ec2.InterfaceVpcEndpointService('com.amazonaws.ap-southeast-2.execute-api'),
privateDnsEnabled: true,
// Choose which availability zones to place the VPC endpoint in, based on
// available AZs
subnets: {
availabilityZones: ['ap-southeast-2a', 'ap-southeast-2b']
}
});
// Create a S3 bucket for VPC Flow Logs - important for debugging.
const logsBucket = new s3.Bucket(this, "myLogs", {
bucketName: 'my-logs',
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
enforceSSL: true,
accessControl: s3.BucketAccessControl.LOG_DELIVERY_WRITE,
encryption: s3.BucketEncryption.S3_MANAGED,
intelligentTieringConfigurations: [
{
name: "archive",
archiveAccessTierTime: cdk.Duration.days(90),
deepArchiveAccessTierTime: cdk.Duration.days(180),
},
],
})
const vpcFlowLogRole = new iam.Role(this, "vpcFlowLogRole", {
assumedBy: new iam.ServicePrincipal("vpc-flow-logs.amazonaws.com"),
})
logsBucket.grantWrite(vpcFlowLogRole, "vpcFlowLogs/*")
// Direct flow logs to S3.
const vpcFlowLogs = new ec2.FlowLog(this, "vpcFlowLogs", {
destination: ec2.FlowLogDestination.toS3(logsBucket, "vpcFlowLogs/"),
trafficType: ec2.FlowLogTrafficType.ALL,
flowLogName: "vpcFlowLogs",
resourceType: ec2.FlowLogResourceType.fromVpc(vpc),
})
/* *
* Lambda Function
* Feel free to change it as you see fit
* For example, you might prefer to use EC2 instead of Lambda function.
* */
const lambda_layer_path = path.join(__dirname, "PATH_TO_CODE");
const lambda_layer = new lambda.LayerVersion(this, "LambdaBaseLayer", {
code: lambda.Code.fromAsset(path.join(lambda_layer_path, "layer.zip")),
compatibleRuntimes: [lambda.Runtime.PYTHON_3_10],
});
const lambdaFunction = new lambda.Function(this, "myFunction", {
functionName:"myFunction",
runtime: lambda.Runtime.PYTHON_3_10,
code: lambda.Code.fromAsset(lambda_layer_path),
memorySize: 1024, // Set memory size to 1024MB
architecture: lambda.Architecture.ARM_64,
handler: "main.handler",
timeout: cdk.Duration.seconds(600),// 10 minutes
layers: [lambda_layer],
role: lambdaRole,
});
// Create a resource policy for the AWS API Gateway to only
// allow the VPC endpoint to execute the API.
const privateAPIPolicy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Principal": "*",
"Action": "execute-api:Invoke",
"Resource": [
"execute-api:/*"
],
"Condition": {
"StringNotEquals": {
"aws:sourceVpc": vpc.vpcId
}
}
},
{
"Effect": "Allow",
"Principal": "*",
"Action": "execute-api:Invoke",
"Resource": [
"execute-api:/*"
],
}
]
}
const privateAPIPolicyDocument = iam.PolicyDocument.fromJson(privateAPIPolicy);
// Create a AWS API Gateway Private Endpoint
const myApi = new apiGateway.RestApi(this, 'ApiGateway', {
restApiName: 'My API Gateway',
endpointConfiguration: {
types: [apiGateway.EndpointType.PRIVATE],
vpcEndpoints: [vpcEndpoint]
},
policy: privateAPIPolicyDocument
})
// Lambda Integration - user requests are passed wholsale from API Gateway to Lambda
myApi.root.addProxy({
defaultIntegration: new apiGateway.LambdaIntegration(lambdaFunction)
})
}
}
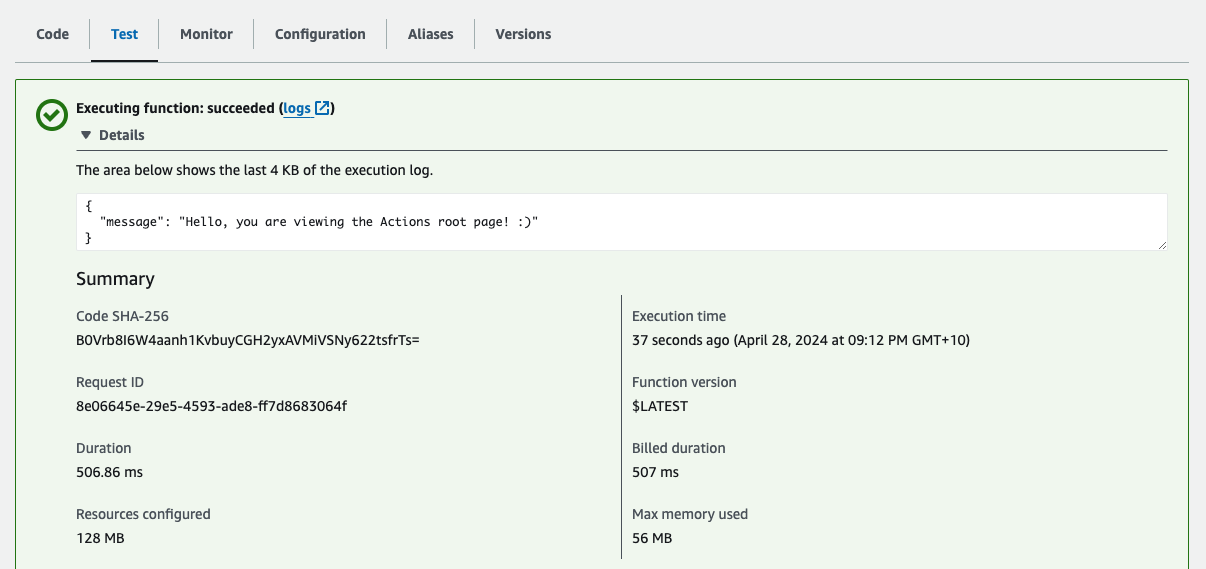
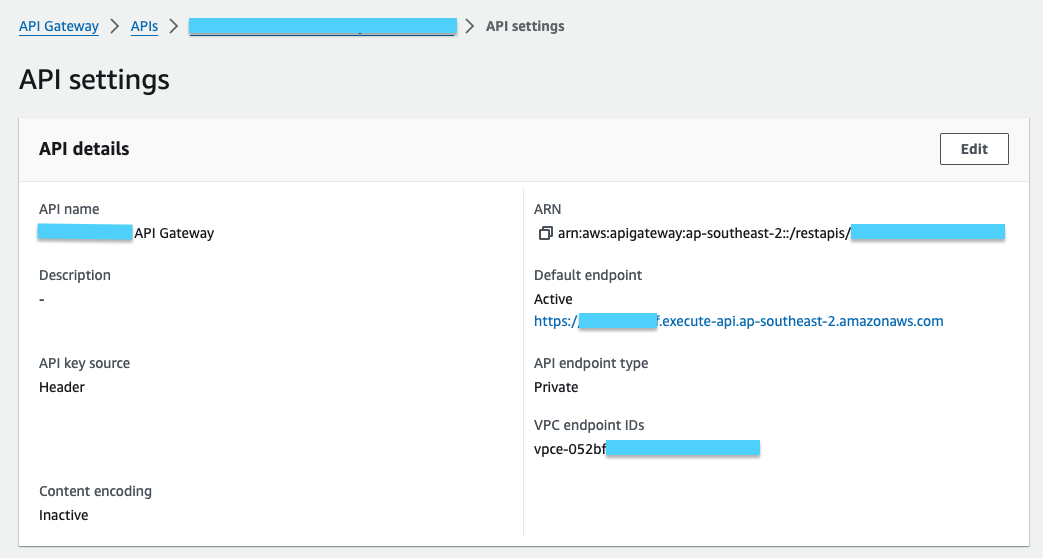
This is how the API looks like after deploying:
Testing the Private Endpoint
To check if the private endpoint works, try invoking it with a Lambda function.
- Create a new Lambda function with the following code
import requests
# Replace these global variables with your account's
VPCE_DNS_NAME = "yourVPCEndpoint.execute-api.ap-southeast-2.vpce.amazonaws.com"
API_GW_ENDPOINT = "yourAPI.execute-api.ap-southeast-2.amazonaws.com"
def lambda_handler(event, context):
# Set up the options for the HTTPS request
url = f"https://{VPCE_DNS_NAME}/prod/" # Enter the path that you want to test
headers = {
'Host': API_GW_ENDPOINT
}
# Make the GET request
try:
response = requests.get(url, headers=headers)
# Log status code and headers
print('statusCode:', response.status_code)
print('headers:', response.headers)
# Return the JSON content if request was successful
# print(response.json())
return response.json()
# Catch any errors that occur during the request
except requests.RequestException as e:
print(e)
return {'error': str(e)}
- Ensure that the Lambda function is in the same VPC as thte Private endpoint, or at least in a VPC that is allowed as stated in the
privateAPIPolicyDocument - Run a test on Lambda
If the connection is successful, you will see a success message along with the JSON payload.