
How to Fix OOM Errors in Spark
What is an OOM Error?
An Out of Memory (OOM) error in Apache Spark occurs when either the driver or executors exceed the memory allocated to them. This typically happens when the memory requirements of your Spark job surpass the configured limits.
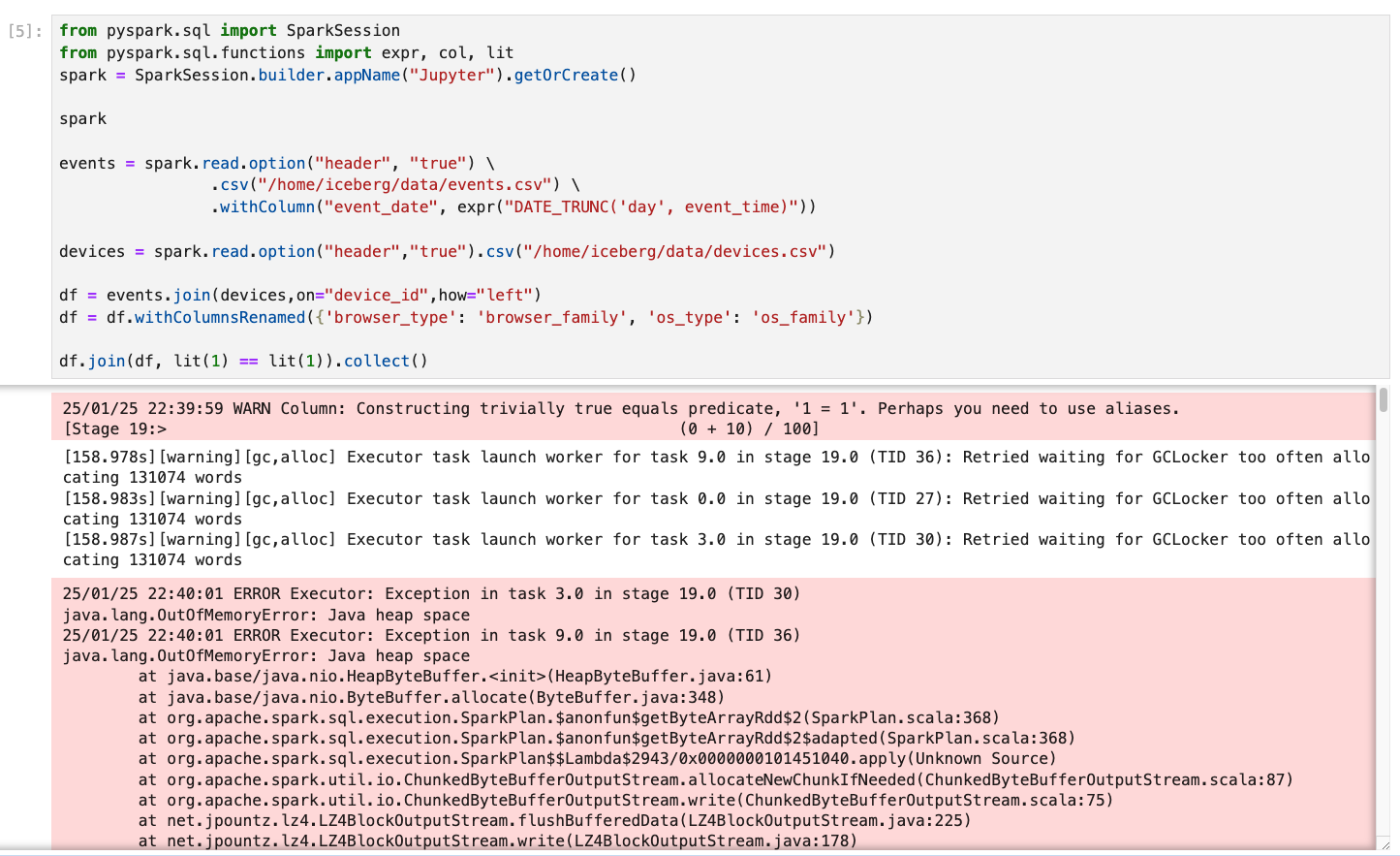
How to Confirm It’s an OOM Error?
Sometimes, the cause of failure is not explicitly labeled as an OOM error. For instance, in Spark 2.0 on AWS Glue, you might encounter subtle error messages like this:
An error occurred while calling o71.sql. error while calling spill() on org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter@74230e8e : No space left on device.
On AWS Glue, you can use metrics such as the Memory Profile Graph to monitor memory usage for both the driver and executors. If some executor memory graphs end prematurely compared to others, it’s a strong indicator of an OOM error. Refer to the AWS Glue documentation for more details.

Causes and Solutions for OOM Errors
Quick Fixes
- Upgrade the Cluster: Start by selecting a cluster with larger memory.
- Adjust Memory Settings: Configure memory settings for both the driver and executors, as detailed in my previous post.
- Leverage Adaptive Query Execution (AQE): For Spark 3.0+, enable AQE to dynamically optimize query execution:
OOM in Executors
1. Data Skew
Certain partitions might be disproportionately large compared to others, causing the associated executors to run out of memory.
Solution: Refer to the “Handling Skew in Spark” section in the previous blog post.
2. Too Few Partitions
As the data volume increases, keeping the number of shuffle partitions constant can result in larger partition sizes. This can exhaust the executor’s memory and even the local disk during intermediate stages.
Solution: Increase the number of shuffle partitions by setting:
spark.conf.set("spark.sql.shuffle.partitions", <new_number>)
3. Too Many Cores per Executor
The number of cores determines how many tasks an executor can run in parallel. While more cores can speed up execution, it also reduces the memory available for each task.
Solution: Reduce spark.executor.cores. The optimal range is typically 4–6 cores per executor.
OOM in Driver
1. df.collect()
When using collect(), data from all executors is sent to the driver, potentially overwhelming its memory.
Solutions:
- Use
repartition()to limit the size of data collected by the driver. - Configure the
spark.driver.maxResultSizesetting to allocate more memory for results:spark.conf.set("spark.driver.maxResultSize", "2g") # Example - Avoid using
collect()whenever possible, and instead write the data to external storage.
2. Broadcast Joins
Broadcasting a table requires the driver to materialize the table in memory before sending it to executors. If the table is too large or multiple tables are broadcasted simultaneously, OOM errors can occur. Solutions:
- Increase driver memory with spark.driver.memory.
- Set
spark.sql.autoBroadcastJoinThresholdto a lower value to avoid broadcasting excessively large tables:spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "10MB")
Pro Tips to Avoid OOM
- Monitor Memory Usage: Use the Spark UI to track memory consumption.
- Avoid Excessive Shuffles: Keep shuffle operations minimal, as they are memory-intensive.
Comments