
Optimising Spark - Joins, Shuffle, and Skew
What is Spark?
Apache Spark is a distributed computing engine designed for processing large datasets efficiently. It provides multiple query engines: the RDD API (the foundational, low-level abstraction), DataFrame and Dataset APIs available in various programming languages, and Spark SQL for working with structured data using SQL syntax. For a detailed explanation of query engines, check out my previous post.
Spark is significantly faster than its predecessor, Hive, which primarily relies on disk-based storage. Spark excels by leveraging in-memory processing, reducing reliance on disk I/O. It only spills to disk when data cannot fit in memory, thus optimizing memory usage is crucial to avoid this, as excessive disk use can degrade Spark’s performance and making it behave like Hive.
Spark Architecture
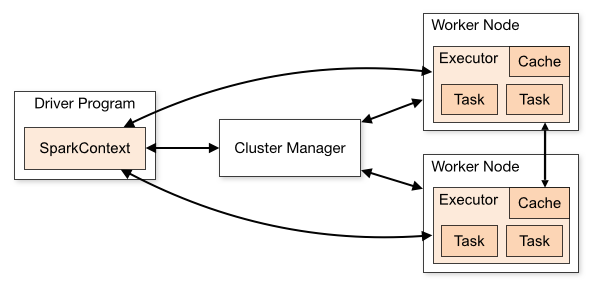
Spark operates with three primary components:
Plan
- Lazily evaluated: Execution occurs only when explicitly triggered, such as with
df.collect().
Driver
- Acts as the “Coach” or the “brain” of the application.
- Determines when to stop lazy evaluation, decides how to join datasets, and sets the level of parallelism for each step.
- Key settings:
spark.driver.memory:- Allocates memory to the driver process.
- Low values can lead to disk spills or out-of-memory errors.
- Default: 2GB. Increase for complex queries (up to 16GB, depending on your workload).
spark.driver.memoryOverheadFactor:- Percentage of memory reserved for non-heap tasks (e.g. JVM overhead).
- Increase this value for complex plans that require more processing.
Executors
- Act as the “Players” that execute tasks assigned by the Driver.
- Key settings:
spark.executor.memory:- Memory allocated to each executor.
- Low values can cause disk spills or out-of-memory errors.
- Test with different values (e.g., 2GB, 4GB, 8GB) to find the optimum configuration.
spark.executor.cores:- Determines the number of tasks each executor can run in parallel.
- This setting is also constrained by the number of cores in a single executor.
- Optimal range: 4–6 cores per executor. Higher values may lead to out-of-memory errors.
spark.executor.memoryOverheadFactor:- Percentage of memory reserved for non-heap tasks like UDF execution.
- Increase for workloads with many complex UDFs.
Cluster Manager
- Acts as the “Manager” of the team.
- Allocates resources to Spark applications and manages executors.
- Examples: Kubernetes, Hadoop YARN.
Types of Joins in Spark
Shuffle Sort-Merge Join
- Default join strategy since Spark 2.3.
- Suitable for joining two large datasets.
- Example:
result = df1.join(df2, "id")
2. Broadcast Hash Join
- Faster as it avoids shuffling.
- Best when one side of the join is small enough to fit in memory.
- Controlled by
spark.sql.autoBroadcastJoinThreshold(default: 10MB). Recommended range is between 1MB to 1GB. - Example:
from pyspark.sql.functions import broadcast result = dfLarge.join(broadcast(dfSmall), "id")
3. Bucket Join
- Faster as it avoids shuffling by pre-bucketing tables.
- Ideal for queries with multiple joins or aggregations.
- Tables are bucketed by a key (e.g.
user_id) and divided into buckets via modulus operation. - Buckets of one table align with those of another (e.g.,
bucket1of table A matchesbucket1of table B). - Best practice: Use bucket counts as powers of 2 (e.g. 16).
- Drawback: Initial parallelism is limited by the number of buckets.
- Example:
# Bucket the Users Table users.write \ .bucketBy(4, "user_id") \ .sortBy("user_id") \ .mode("overwrite") \ .saveAsTable("bucketed_users") # Bucket the Transactions Table transactions.write \ .bucketBy(4, "user_id") \ .sortBy("user_id") \ .mode("overwrite") \ .saveAsTable("bucketed_transactions") # Read the bucketed tables bucketed_users = spark.table("bucketed_users") bucketed_transactions = spark.table("bucketed_transactions") # Perform the join result = bucketed_users.join(bucketed_transactions, "user_id")
How Does Shuffling Work?
Shuffling is triggered by wide transformations that aggregates data such as groupByKey, reduceByKey and joins. Narrow transformations like map and filter do not trigger a shuffle.
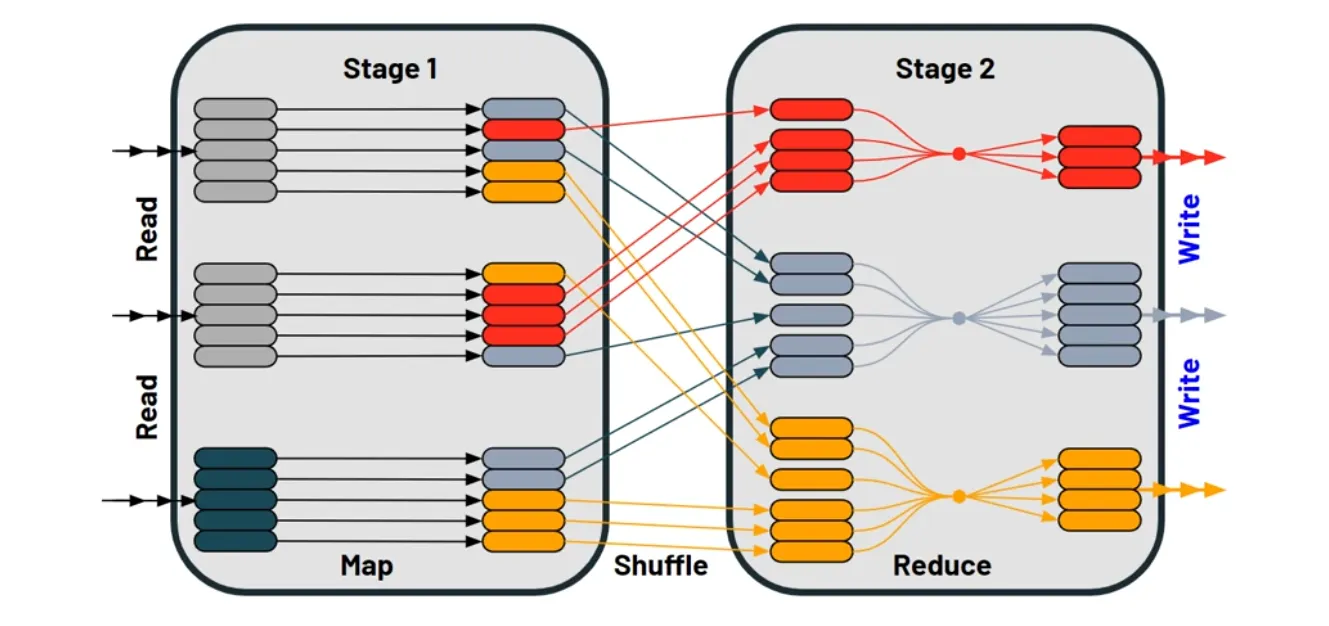
1. Map Phase
- Spark processes the data into key-value pairs for grouping, sorting, or other transformations.
- Example: For a
groupByKeyoperation, Spark maps rows into key-value pairs (e.g.,user_idas the key) if it’s not defined already.
2. Shuffle Phase
- Redistributes data across executors based on keys (in order to process data in parallel).
- Involves network I/O to transfer data between executors (and disk I/O if data exceeds memory).
- Spark determines partitions using a modulo operation on the key (e.g.
user_id). - Default number of partitions: 200 (
spark.sql.shuffle.partitions).
3. Reduce Phase
- Aggregates or processes shuffled data within each partition.
- Example: For
groupByKey, Spark groups rows by key (e.g.user_id) and applies aggregations likeSUM.
Handling Skew in Spark
Data skew occurs when some partitions hold significantly more data than others, leading to performance bottlenecks. Symptoms include long job runtimes, high CPU utilization (e.g. stuck at 99%), or outliers in partition sizes. You can also detect skew by checking the summary metrics and identifying which tasks take the longest in the Spark UI. A more scientific way to detect skew is to use a box and whisker plot to check for outliers. Here are some methods to reduce skew.
For Spark 3.0+:
- Enable Adaptive Query Execution (AQE) with
spark.sql.adaptive.enabled = true.
For Spark <3.0:
- Use Salting:
- Add a random “salt” column to the dataset before grouping to distribute data more evenly across partitions.
- Example:
df.withColumn("salt_random_column", (rand * n).cast(IntegerType)) .groupBy(groupByFields, "salt_random_column") .agg(aggFields) .groupBy(groupByFields) .agg(aggFields) - Note: For metrics like
AVG, decompose intoSUMandCOUNTbefore dividing.
Filter Outliers
- Identify and process outliers separately to reduce skew.
Tips for Optimizing Shuffling:
- Avoid shuffling large datasets whenever possible; aim for tables <100GB.
- To change the number of partitions, please use
spark.sql.shuffle.partitions. It is linked tospark.default.parallelism(used in the RDD API, which is lower-level). - Use
explain()to inspect join strategies and execution plans.
Comments