
Supervised Learning Models for Structured Data
Context
In the previous post, I explored and analysed the Telco Churn dataset to gain a better understanding. This led me to think: why don’t I create a one-stop repository of all the popular ML algorithms to identify churn, or supervised learning in general?
Well, guess what, here’s the repository! 🥳
Alright, I admit – I might have fallen into a rabbit hole of ✨machine learning✨, and maybe you didn’t need one in the first place. However, I believe that the repository will be beneficial to me in the long run (and hopefully to you) because I could view all the popular ML algorithms and key information on a single page and experiment rapidly.
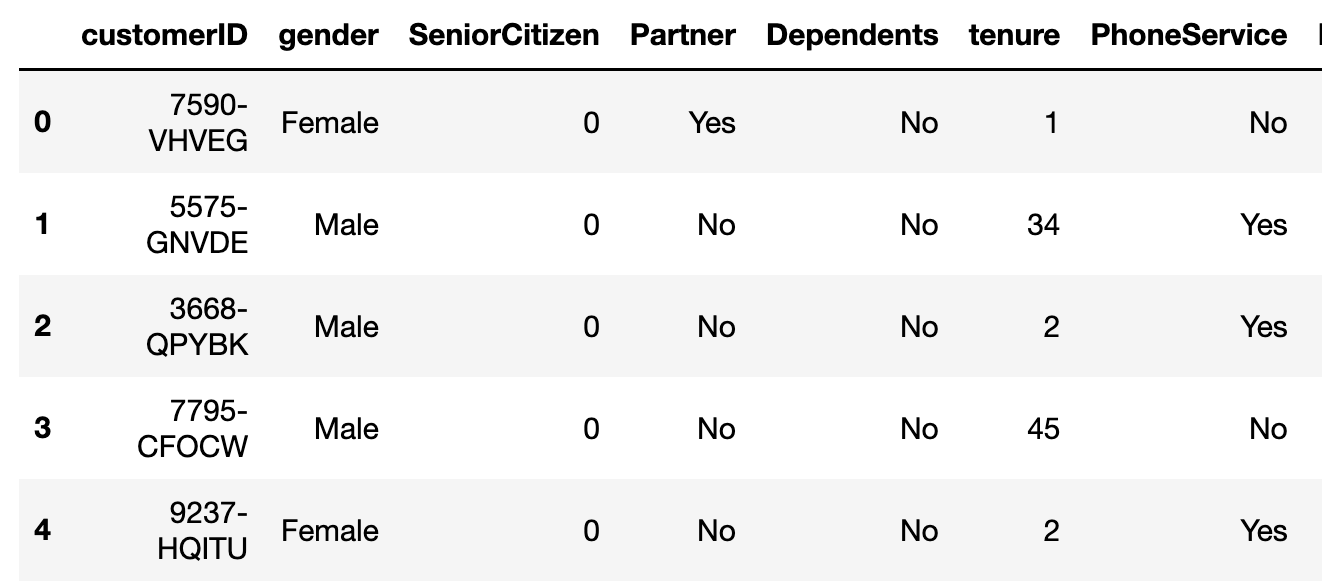
The focus of this post will be on structured data (aka tables with a fixed schema), as seen in the image below. In the future, I will also extend this repository to cover other data formats like images, videos, natural language etc, so stay tuned!
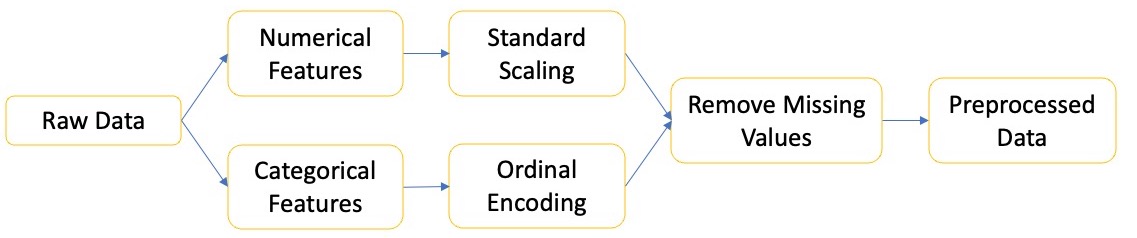
Preprocessing Steps
I have tried to reduce the number of preprocessing steps possible as the focus of this blog is on the ML algorithms (not best practice btw). However, if you are interested:
Supervised Learning Models for Structured Data
In my repository, I have added the following algorithms for experimentation:
- Linear Models
- Logistic Regression
- Elastic Net
- Support Vector Machine (SVM)
- K Nearest Neighbours
- Naive Bayes
- Decision Tree
- Ensemble Methods
- Random Forest
- Adaboost
- Gradient Booster
- Majority Voting Classifier
- Weighted Classifier
- Multi-Layer Perceptron
Model Selection
To quicken my experimentation process, I would run this script to determine the best algorithm(s):
# Import relevent classes from scikit-learn
# For ensemble model -- change as desired
model_1 = LogisticRegression(random_state=0)
model_2 = RandomForestClassifier(n_estimators=100, random_state=0)
model_3 = GaussianNB()
models =[
LogisticRegressionCV(cv=5, random_state=0),
ElasticNetCV(cv=5, random_state=0),
SVC(random_state=0),
KNeighborsClassifier(n_neighbors=50),
GaussianNB(),
DecisionTreeClassifier(random_state=0),
RandomForestClassifier(random_state=0),
AdaBoostClassifier(n_estimators=100, random_state=0),
GradientBoostingClassifier(n_estimators=100,
learning_rate=1.0,
max_depth=10,
random_state=0),
VotingClassifier(estimators=[('lr', model_1), ('rf', model_2), ('gnb', model_3)],
voting='hard'
),
VotingClassifier(estimators=[('lr', model_1), ('rf', model_2), ('gnb', model_3)],
voting='soft', weights=[2, 1, 2]
),
MLPClassifier(solver='adam',
activation = 'relu',
learning_rate_init = 0.001,
alpha=1e-5,
hidden_layer_sizes=(15,),
max_iter = 400,
random_state=1
)
]
scores={}
for model in models:
model_name = model.__class__.__name__
model.fit(X_train, y_train)
recall = model.score(X_test, y_test)
recall = round(recall, 4)
scores[model_name] = recall
print(f"Accuracy (recall) of {model.__class__.__name__} is {round(recall, 4)}")
best_score = max(scores.values())
best_model = max(scores, key=scores.get)
print(f"Best score is {best_score} by {best_model}")Output:
Accuracy (recall) of LogisticRegressionCV is 0.7967
Accuracy (recall) of ElasticNetCV is 0.269
Accuracy (recall) of SVC is 0.7953
Accuracy (recall) of KNeighborsClassifier is 0.7818
Accuracy (recall) of GaussianNB is 0.7534
Accuracy (recall) of DecisionTreeClassifier is 0.7193
Accuracy (recall) of RandomForestClassifier is 0.7918
Accuracy (recall) of AdaBoostClassifier is 0.7974
Accuracy (recall) of GradientBoostingClassifier is 0.7612
Accuracy (recall) of VotingClassifier is 0.7989
Accuracy (recall) of VotingClassifier is 0.774
Accuracy (recall) of MLPClassifier is 0.7967
Best score is 0.7974 by AdaBoostClassifier
Bonus - Refactor Code for a Model Training Job
After selecting the best-performing model, you may want to submit a training job to AWS Sagemaker or another cloud provider. In that case, you have to refactor your code from a Jupyter notebook .ipynb to a Python .py file. Here is a sample code from the repository.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OrdinalEncoder
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import AdaBoostClassifier
def structured_data_classification():
print("Reading data...")
df = pd.read_csv("data.csv")
df.drop("customerID", axis = 1, inplace=True)# Drop id column
print("Preprocessing data...")
y = df.pop('Churn') # Label
# Separating Numeric and Categorical Features
numeric_features = ["tenure", "MonthlyCharges", "TotalCharges"]
all_features = list(df.columns)
categorical_features = [c for c in all_features if c not in numeric_features]
# Extra preprocessing for this specific dataset
for x in numeric_features:
df[x] = pd.to_numeric(df[x],errors='coerce')
X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.2)
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OrdinalEncoder(dtype = 'int64'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
model = AdaBoostClassifier(n_estimators=100, random_state=0)
print("Training data...")
pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', model)
])
pipeline.fit(X_train, y_train)
recall = pipeline.score(X_test, y_test)
print(f"Accuracy (recall) is {round(recall, 4)}\n")
if __name__ == '__main__':
# TODO: add arguments for inputs
structured_data_classification()Here’s the link to the repo, happy coding!
Comments